![]()
![]()
5.6.014
Release notes Skribenta CCMS
Skribenta Web (the Skribenta User interface) was previously developed in a separate branch. Now Skribenta CCMS and Skribenta Web are developed in the same branch and are sharing the release information.
We have changed the case management tool we use. Because of this the case numbering has been reset. This is why the numbering doesn't follow from the previous release.
Improvements
Find and filter texts in the current file
You can use the Find panel (Ctrl+F) to search for text in the view. Now, another find function is introduced. It contains a filter function for decreasing the number of hits. Use it like this:
-
Put the caret inside a file
-
Press Ctrl+Shift+F. A panel is presented, containing all the paragraphs and titles in the file

In this example, there are 125 texts (paragraphs and titles) in the file.
-
Write some characters, in this case "call", and the list will be filtered, now only 13 hits:

-
Click on the hit you are looking for - the caret is moved to the place
You can also put the caret inside a publication group and press Ctrl+Shift+F - this will bring up the same panel as if you had clicked on the Tree button:

Callout improvements
There are two different icons involved when a Callout is presented:
 An embedded Callout drawing element. The icon is placed at the bottom left - it was at the top left before.
An embedded Callout drawing element. The icon is placed at the bottom left - it was at the top left before.
 An image pointing to a Callout file.
An image pointing to a Callout file.
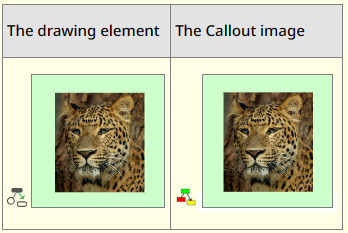
The caret position around a Callout drawing element has been improved. Moving the caret, step by step, results in these positions:
 The caret is before the drawing element
The caret is before the drawing element
 The caret is in the beginning of the drawing element.
The caret is in the beginning of the drawing element.
The resize icon is now a rectangle in the upper right corner (just like for other images). It was previously a circle in the lower right corner.
 The caret is standing on the image shape
The caret is standing on the image shape
 The caret is at the end of the drawing element. The caret was previously in the lower left.
The caret is at the end of the drawing element. The caret was previously in the lower left.
 The caret is after the drawing element.
The caret is after the drawing element.
The positions around a Callout image are exactly the same.
When a shape is dragged inside a drawing, dotted lines appear for alignment. Now 6 more lines appear for aligning a shape to different positions in relation to the drawing area.



Images and Zoom
One image can be part of a content file in four different ways:
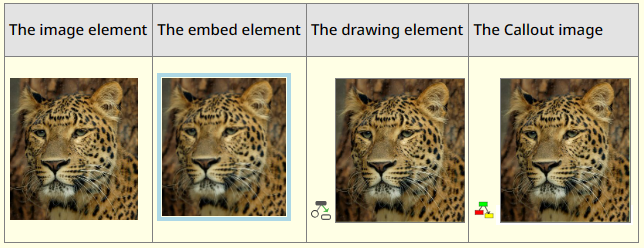
The embedded element does not point to the actual image - it's just a screenshot. The other three all points to the same image and updating the image will affect all.
Hovering over the image and embed elements will present the image and embed icons in the lower left corner:


Clicking on the icon will bring up the toolbar.
Images are placed in folders.

Images can also be found in the Search aspect:
Double-clicking on any image in the different views will open the Zoom view.

In the Zoom view you can zoom in and out with the mouse wheel. The zoom range is between 1% and 100 000%. The view can also be dragged around with the mouse.

Hovering over the toolbar icon in the upper left corner will open a toolbar:
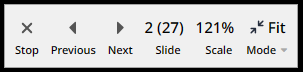
The toolbar presents the number of images in the view, in this case 27. Since the images can be presented one by one, the Zoom view acts like a kind of "slide show".
The number of included "slides" depends on where the image was expanded:
-
Inside a content file
Each image in the file becomes a slide.
-
Inside a folder
Each image in the folder becomes a slide.
-
Inside the Search aspect
Each found image becomes a slide.
Variable type in a configuration file
There is a type column in a configuration file (a recipe). Now you get support for inserting a valid type.
If you write a character in the cell, a dropdown appears:
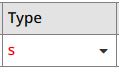
Clicking on the dropdown will present all valid types:
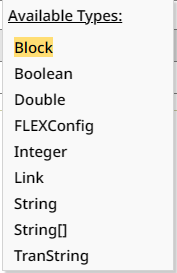
As long as the type is not valid, it will be presented in red.
Note. The letter case for a type is not significant.
Upgrade to FOP version 2.9
Apache FOP 2.9 has been released and includes several good functional improvements. For example, it supports:
font-selection-strategy = character-by-character
This has been a major drawback with FOP so far, so it will be a great improvement for our ability to provide FOP based PDF stylesheets to our customers.
The following third party software has been upgraded:
-
Batik: 1.14 to 1.17
-
commons-io: 2.4 to 2.11.0
-
PDF box: 2.0.19 to 2.0.29
-
FOP: 2.8 to 2.9
File references in publish warnings
Publishing warnings can be augmented with a file reference that points to the file that contains the element that the warning is associated with. This can be turned on with the publish option "Show file references in warnings".
This is an example of a standard publishing error message:
1 Include failed: File 'id(787619999)Test file 2.xml' was not found
This is an example of a publishing error message when the Debug option "Show file references in warnings" is selected:
1 Include failed: File 'id(787619999)Test file 2.xml' was not found, located in file: /DMS/Files/Test/id(77509)ix(77512)v(a1)Test file 1.xml
Spell-checker for publishing
Spell-check can now be performed during publish. It is integrated with LanguageTool, just as the spell-check during editing.
How to use the publishing spell-checker
The publishing spell-checker is activated with a publish option, found in the toolbars for a publication, a publication group or a content file. The option is located under Publish > Options > Spell checker, as indicated in the following image:
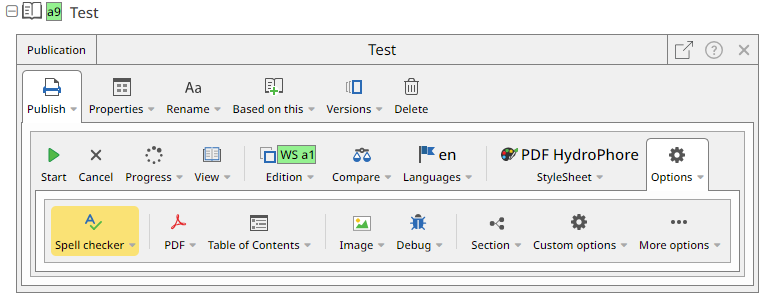
Pressing the button "Spell checker" reveals two options in the form of checkboxes:
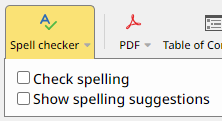
In order for the publishing spell-checker to execute the checkbox "Check spelling" must be selected.
The other option "Show spelling suggestions" can be used together with the option "Check spelling". It will add suggestions, both in the publishing log and in the output format. Here is one example where publishing is done to PDF, with and without the option "Show spelling suggestions".
XML (content file):

Publishing with both "Check spelling" and "Show spelling suggestions" selected:
Publish log:

PDF:

Publishing with "Check spelling" selected but without "Show spelling suggestions":
Publish log:
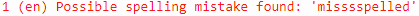
PDF:

Features of the publishing spell-checker
The publishing spell-checker has a number of features:
-
Spell-checking is done on the document text after all of Skribenta's DOM filters have been executed which is right before the stylesheet starts to transform the content from XML into the output format. This means for example:
-
The text has been translated to the target language.
-
Includes and variables have been processed.
-
NS-loops have been processed.
Hence, you will spell-check a corpus of text that is as close as possible to the text that you see in the output format.
-
-
The publishing spell-checker replaces object and title references with their target values before spell-checking starts. This means that the paragraph can be spell-checked as it is presented in the output format which enhances the grammatical quality.
-
Spell-checking works for multi-language publications.
-
As for the spell-checker in Skribenta web, the publishing spell-checker ignores spelling mistakes that are added to the global dictionary.
-
The publishing spell-checker replaces certain elements with dummy texts before the spell-checking begins to make the spell-checking more accurate. After spell-checking is done, the original elements are put back in place. For further information about this feature see section .
-
The publishing spell-checker captures spelling mistakes that cross XML tags. Here is one example where a paragraph with a misspelled text is published to PDF with the spell-checker option activated:
XML (content file), the first letter of the misspelled word "misssspelled" is in bold:
PDF, the spell-checker analyses the whole word "misssspelled" even though the first letter is in bold and marks the mistake in the PDF:
-
PDF stylesheets that are based on Excosoft's super stylesheets are fully compatible with the publishing spell-checker meaning that the spelling mistakes will be highlighted without modification of the stylesheet.
Replaced by-feature in the publishing spell-checker
The publishing spell-checker replaces certain elements with dummy texts before the spell-checking begins to make the spell-checking more accurate. After spell-checking is done, the original elements are put back in place.
The following table lists the default replacement rules:
Element description
Element XML
Replaced by
Image
image
"X"
Line break
linebreak
" "
Reference link
link[@type-Reference]
"X"
Page reference
reference[@class='page-reference']
"X"
Index term
indexterm
"" (empty text)
Superscript
phrase[@class='superscript']
"" (empty text)
Subscript
phrase[@class='subscript']
"" (empty text)
Translation hint
phrase[@class='translation-hint']
"" (empty text)
Affix
phrase[@class='affix']
"" (empty text)
Aside from the default replacement rules, it is possible to define custom rules in a recipe, read during publishing, for instance the stylesheet recipe or the publication recipe. Please contact Excosoft if you want to discuss this option for your stylesheet.
Block elements analysed by the publishing spell-checker
The publishing spell-checker analyses texts in the following block elements:
-
paragraph
-
title
-
caption
-
maintitle
-
subtitle
-
data-text
The data-text element is seldom used but is treated as a block element.
Only elements located in the parts "frontmatter", "body" and "endmatter" are analysed, texts at other locations in the XML are ignored.
Texts ignored by the publishing spell-checker
The following table lists texts ignored by the publishing spell-checker. If some part of the spelling mistake is inside the indicated parent element it will be ignored. Apart from this listing, texts added to the global dictionary are also ignored.
Text location
Parent element
Comment
Phrase superscript
phrase[@class='superscript']
Phrase subscript
phrase[@class='subscript']
Phrase value
phrase[@class='value']
Phrase unit
phrase[@class='unit']
Phrase affix
phrase[@class='affix']
Phrase translation-hint
phrase[@class='translation-hint']
Phrase TR.NotFoundTranslation
phrase[@class='TR.NotFoundTranslation']
Automatically created by Skribenta to indicate that a text block has not been translated.
Image
image
Reference
reference
Note - the only reference element exposed to the publishing spell-checker is the page-reference as described in section .
Index term
indexterm
For further information, see section .
Callout drawing
drawing
For further information, see section .
Type Spellcheck
Any element with type = NoSpellcheck
If any parent element up to the root XML level of the document has type NoSpellcheck, the text will not be spell-checked.
This means that you for example can set the type NoSpellcheck on a section, then no text in that section will be spell-checked.
Limitations
Currently, the publishing spell-checker does not spell-check texts found in:
-
Callout drawings
-
Index terms
Support may be added in future releases of Skribenta.
Known issues
Currently, the publishing spell-checker may not be able to detect all spelling mistakes. In some rare cases it may also mark texts erroneously as mistakes. However, it spell-checks almost all texts in a correct way and is therefore useful from a quality point of view in the current state. We will continue the development work and fix the known issues in future releases of Skribenta.
Bugs
List of solved issues
WI409 Copy the list item of the order list then paste in the empty section so that it created the unordered list
Now it will create the correct ordered list when copy paste from an existing one instead of an unordered list.
WI417 Yellow highlights after searching remains
There was an issue where the highlighted word from a search would remain highlighted when opening the file in the Workspace aspect. This has been fixed.
WI418 Checked in Checkbox of Result in Check-in panel
Fixed a UI problem with check-in panel.
WI436 Issues in SBSpellcheck filter
Various issues have been fixed with the publishing filters that is responsible for spellchecking during publish.
WI440 Spellchecker indications shown on top of sticky table headers
Spellchecker indications were shown on top of sticky table headers.
WI442 Spellcheck positioned wrong when expanding inline selection panel
The highlighting of a spelling mistake was positioned wrong when the inline selection toolbar was opened.
WI464 Selecting content of an element when embedded toolbar, selects the toolbar also
The embedded toolbar now can't be selected with Ctrl A inside an element
WI467 Not possible to delete XML element (a drawing)
The Drawing element now should be deleted by using the Cut function (Ctrl-X)
WI469 The caret loops in include file by arrow down/up
Now the carets will stay in correct place when moving around with arrow down/up
WI479 Not possible to explore flat files, compare flat files gives always equal result and is-using gives error
Hid the Compare and the Is-Using functions for flat files.Explore now works for flat files inside Versions
WI480 Switching language on recipe in Nav frame throws error
When selecting a language using the file language icon and then viewing the translations in the Nav frame, an error message was displayed.
WI483 Not possible to publish a file in Tools when standing in the content frame
Publish option is now shown in Toolbars and Tools frame for master files and recipes
WI484 Search query using a wildcard in translation project throws an error
The error now will be more user friendly instead of the original from Lucene
WI486 Browse window changes location in a panel when navigating upwards
Fixed a problem related to the browse box in panels.
WI501 Don't allow to add Format element into every textbox field in Toolbar
It is now not possible to create inline elements inside text fields on toolbar tabs.
WI502 Embed toolbar and floating toolbar of user management
Fixed the appearance of the User toolbar in User management.
WI508 When pasting a file into an xml file the behaviour is different than when creating an include from the menu
Includes are now created the same way regardless if its created via the paste function "Paste as include" or via the top toolbar "Blocks > Include".
WI511 Error when clicking Location in Translation or Improve project
The Location and Used By buttons are no longer available for Translation or Improve project files.
WI514 Compressing a publication having a floating toolbar open, closes toolbar
Now the publication's floating toolbar will not be closed when compressing the publication.
WI517 Searching for ? or * in file search aspect throws error
Made eventual error message from search engine more user friendly.
WI518 The spellchecker suggestion line takes space in the layout
The spell checker highlighting created empty spaces on the screen, that was fixed.
WI537 File name is appended in link when making link in a link element without text but has a reference element.
Changing link destination for links with reference elements appended the link destination title text to the updated link which is wrong, this was fixed.
WI541 Misspellings are not highlighted in editor
Misspellings were not highlighted in editor after search on server.
WI546 Extending a selection in progress panel
Improved possibility to select text in the publish log.
WI547 Can not transform include of Inline element to link
An inline include can now be transformed to a link.
WI560 Translation job buttons disappear when switching user role
Translation job buttons disappeared when changing user role.
WI562 "more"-button shall not be visible in blocks in view similar tab in a content file
The More button was visible for blocks on the Similar tab in a content file.
WI564 User can replace a configuration file with an image file in a publication
When browsing for recipes it will no longer list images.
WI568 Labels in generalized blocks should be consecutive
Bug fix: Labels in generalized blocks should be consecutive and not the same. Variable phrases, for example, got the same label if the variable name was the same. This resulted in two blocks in the memory which was not correct.
WI570 No way to insert secondary or tertiary indexterm nor open attributes panel
Added tooltip text to the indexterm element describing how to insert the secondary or tertiary indexterm.
WI571 Not possible to compress a wrapper without a title, having child block element as the first child, by double-click
It was not possible to compress (by double-click) a wrapper element without a title, having a block element as the first child.
WI576 Implement to Hide high level functions for different roles
Configured panel items for each user role.
WI577 SBSpellChecker: Problem with linebreaks
Developed support for defining rules for nodes that shall be replace with custom text before the DOM is being spell-checked. The rules are defined in a recipe that is read during publish. The rules work similarly as the spell-checker in Skribenta web.
WI578 Wrong variable value is shown when variable is of type Int
Integer variable values were not displayed correctly when using view option "Variable values", this was fixed.
WI579 Search result counter is wrong when searching within a folder
Removed the counter when searching inside a folder
WI584 SBSpellChecker: Problem with object references
Fixed a problem with SBSpellChecker publish filter.
WI588 SBSpellChecker: Problem with function addThisMistake
General improvements and bug fixes in the publish spell-check filter.
WI621 Transform section to Make file doesn't work
Transform section to Make file did not work.
WI625 Translations in a paragraph containing only indexterm elements is not received
Translations in a paragraph containing only indexterm elements were not received.
WI627 Expanding a publication group with many publications takes a long time
Performance improvements when expanding tree items such as PublicationsGroups.
WI636 Not possible to edit attributes in toolbar (apply button not active)
Existing customer property values could not be changed, this was fixed.
WI638 No horizontal scrollbar in publication group toolbar when browsing files
Long file names or file names in deep folder structures could some times not be fully seen in some panels, this was fixed.
WI640 Add status to translations
It is now possible to set status Approved/Not approved on translations. By default all new translations have status "Not approved".
WI641 Unwrap an inline element by pressing Delete or Backspace key
It is now possible to unwrap an inline element by using the Delete or Backspace key.
WI642 Upload files to folder without overwriting existing files
It is now possible to upload files to a folder without overwriting existing files with the same names.
WI647 When creating a publication, radio buttons for folders should not be available when browsing for master/recipe file
Removed radio buttons from folders when selecting content and configuration file via the Browse button for a publication.
WI648 File content should be reloaded when overriding by uploading file to folder
A file that was updated with new content via the Upload function seemingly had the same content after Upload. This was a refresh problem in the client that was fixed.
WI650 Wrong text in login window
Updated texts in login window.
WI665 Database is initialized twice
There was a bug that could cause the database to be initialized twice. This has been fixed.
WI671 Concurrency issues with ThreadContext manager
You could randomly get strange behaviour when Publishing such as Progress text not showing or Nullpointer exceptions. This has been fixed.
WI672 Unable to publish after randomly repeating the publish
The progress info would stop showing when publishing after a handful publications being published. This has been fixed.
WI677 Wrong caret position in Rename Panel
Cursor could end up at illegal positions in the rename file panel, this was fixed.
WI686 Should be clear message when clicking Similar button of paragraph has callout or empty paragraph
Improved feedback message when Similar button is pressed for an empty paragraph and for a paragraph having a callout image.
WI687 Improvement: Add new icon/button on top left of image
New dynamic icon developed that can be used to access the image panel.
WI691 Can not close Floating toolbar
The paragraph toolbar did not close when the paragraph element was deleted.
WI692 Some image files don't show in folder
Some image files were not visible when expanding the parent folder.
WI693 Various Callout bugs
The text boxes on the shape toolbar tabs now have a maximum width. The blue or grey border around shapes has been removed.
WI695 Wrong publish state after publishing multiple publications
Fixed an issue where the publishing states still showed Prepared even when the publishing was done. This occurred when publishing multiple publications.
WI696 The copy button doesn't work in the shape.
Fixed a problem with copy/paste of shapes in drawing.
WI697 The image panel should be closed when clicking apply button
The drawing panel is now closed after an image has been added.
WI700 The image cannot be viewed if any language is set to the image props
An image could not be viewed if any language was set in the image props.
WI715 QR codes and barcodes do not work with FOP under Linux
QR codes and barcodes did not work with FOP under Linux.
WI716 Fragmented site publisher cannot create subfolders
Fixed an issue in FragmentedSitePublisher that sometimes led to that output folders could not be created.
WI717 Internal Skribenta Web version a1234 should be shown in UI when logging in
Changed how Skribenta version is presented when Skribenta is loaded.
WI728 Clicking Enter for create new listitem when caret at the end of title of list
Pressing Enter at the end of a list title created a paragraph at wrong position in the list, this was fixed, now the same action results in a new list item at the beginning of the list.
WI730 Tags are shown in search panel when tags are shown in a file
Tags were shown in the Search aspect when tags were shown in a file.
WI735 Duplicate items loaded into navigation tree
Fixed a rare issue where a user could occasionally see duplicate items in the navigation tree. We have added some checks to avoid this occurring.
WI736 Skribenta web spell checker markup becomes corrupt when moving tab between frames
The spellchecker markup is now correct when moving a tab between the Nav and Content frames.
WI737 Creating a new folder with same name as existing, user get java.lang.exception
Improved warning message when user tries to create a folder or file with a name that is the same as an already existing folder or file.
WI738 File extension is lost when renaming a file
The file extension of a renamed file will now be preserved if the extension is omitted during the rename action.
WI740 Tooltips on lock and save icons are obsolete
Changed functionality for the Lock button. Now it only indicates if a file is locked/unlocked by you. Tooltip texts on the Lock and Save buttons are also updated.
WI741 User can edit button label in Translation
It was possible to edit button names on blocks in the translation job files.
WI742 Missing words when transform a section to link
When a section, containing multiple words in the title, was transformed to a link, the resulting file was missing words in the file name.
WI746 Opacity issue for SVG images using FOP
The PDF producing engine FOP renders SVG images using the opacity attribute with bad quality. Use fill-opacity and stroke-opacity instead. A publish method was implemented that automatically converts opacity to fill-opacity and stroke-opacity. This method can be activated by setting the following variable to true: Skribenta.Publish.Images.FixSvgOpacityForFop
WI748 Overview file is not shown when content frame is hidden
If Overview was open in a tab in Content frame and Content frame was hidden, nothing happened when the Overview aspect button was pressed, this was fixed.
WI749 Export function in Skribenta web does not work
Now the exported zip file will shows the content correctly instead of empty or corrupted zip file.
WI753 JNLP Files missing jar dependency
User were unable to start the jnlp clients due to missing dependencies. This has been fixed.
WI754 ClientInstaller fails when attempting to install using https connection
Some Users had issues downloading and running the Skribenta Client installer when https is being used. This has been fixed.
WI755 Baseline is not checked out if the workspace folder is manually checked out
Now the baseline will also be checked out when checking out a workspace version manually.
The old baseline update call is removed to prevent the error saying "Baseline is not last in branch"
WI756 Error when locating a PDF from a link
Improved message when file cannot be found in workspace when pressing Location button.
WI758 Add "%" to displayed table column widths next to the top toolbar
Skribenta now presents the table column widths in percentage as a message next to the top toolbar when the column widths are changed by dragging the column separators.
WI760 Folders disappears in workspace, and files are shown twice
Some folders were not visible in the workspace, and some files were shown twice.
WI761 The file without content when create file with number at beginning of title in workspace aspect
When creating a file with a number at beginning of the file title, the file was created without file name extension.
WI762 The content should be undo when clicking close or cancel button of the file has not checkout yet
Did not undo the editing made before canceling a file check out.
WI763 Database exception message to user is given upon closed database connection
The exception message now will be more user friendly along with a confirmation to redirect users back to the login page
WI766 Cursor can be moved to illegal positions in panels
The cursor could sometimes end up at strange positions in panels, this is fixed.
WI767 Cursor moves to float button in panels when arrow down is pressed
Disabled possibility to reach the top panel buttons "float", "help" and "close panel" with arrow keys. When using the keyboard, use Escape to close the panel and F1 to reach the help.
WI769 Ctrl+Arrow up does not work properly for closing panels
Now Ctrl + Arrow Up will work properly for closing panels and no error will be thrown
WI771 Red color text appears in toolbar
Red color text appeared in the link toolbar when creating a link as variable value in a configuration file.
WI773 Toolbar is hidden by dragging and fix minor bugs
Floating panels can now not be dragged outside the browser edge. Fixed UI issues related to the action when a file is closed. Removed a temporary view chain from UI when Skribenta is reloaded. Fixed coloring issues of warning messages-.
WI775 Decode S5 param downloadName on server side
The Get button, used for downloading published output, did not work. This is fixed.
WI776 Wrong file name when creating a file from a template (Master, Module, Overview, Recipe)
Fixed a problem with file naming of a newly created file.
WI777 Users should not be allowed to drop files inside a Publication group.
Disabled possibility to drag and drop files in publication aspect.
WI778 If the same file is included many times in same publication, used by lists same publication many times
Assume that content file A is used by publication P and that another content file B is included many times in content file A. Doing Used By on content file B would then lead to that publication P is equally many times as the number of times it was included in content file A. The correct behavior is that publication P is listed only once, this was fixed.
WI782 System messages are shown in red at certain cases
If one red message appears, the following messages become red even when they are not critical.
This has been fixed.
WI786 Unable to create domain with template
It is now possible to create a new Skribenta domain with a template.
WI787 Should be show confirm popup when copy url then paste into paragraph
Created confirm popup-list for the case when a URL is pasted to a Skribenta content file. The confirm popup-list has three options: Paste as link, Paste as text only, Cancel
WI789 SkribentaClient is unable to download a published pdf
Fixed an issue that cause the client to failed to download the PDF from the server. The client would show the publishing status as 'Failed'
WI790 "Don't spellcheck this word" should set a type=NoSpellcheck value, not class on the phrase
The nospellcheck phrase inserts a phrase with type="NoSpellcheck".
WI812 Z-index for spelling mistakes is too high compared to image Slide
Spell check mistakes was seen in above the image preview window, this was fixed.
WI815 Technical writer cannot expand all translations in a block - "not editable"
Now TechnicalWriter can also be overruling editables
WI820 Workspace checkin not possible in Skribenta Client
When attempting to checking the workspace using the Skribenta Client an error message would be shown with the text "Could not update file".This has been fixed.
WI822 Delete button doesn't work in phrase element
The Delete button did not work in a phrase element.
WI830 Can not expand folder of browse in image shape panel.
Fixed an issue where the browsing panel would close when browsing for images to add to a dml drawing.
WI831 Apply button in ReferenceLink panel should activate if Target ID and Type contains text
The Apply button was not activated in the expected way in panels for adding and editing reference elements, this was fixed.
WI834 Image resource can not be started slideshow
Fixed an issue where the image slideshow would not activate after double-clicking on an image.
WI840 Translation: Source language text layer in a translation block should not have status "Not approved"
Source language text layer in a translation block should not have status "Not approved". This has been fixed.
WI849 More Callout bugs
Fixed some more callout bugs.
WI850 Translation: The Process buttons in a TP should be the same (and in the same order) as in an IP
The Process buttons in a translations project is now displayed in the same order as for an improvement project.
WI858 User is able to select and hide "New name" label in rename panel
Fixed an issue where you could select and hide the rename field label.
WI860 SBSpellChecker - Variable phrases should not be replaced by X
Removed default rule that replaces variable phrases with the letter X from the publish spell checker.
WI863 Rename file, folder, publication wrong with dot in name
Fixed an issue when renaming a file and added dots to the filename would cause the file extension to disappear.
WI866 Checksum missing from server info
The checksum was missing from the server info. This information is important to determine exactly what build is being used.